AUTHORS

Andrea Casati
Director Data&AI Financial Services
@BIP xTech

Gabriella Jacoel
Lead Data Scientist Financial Services
@BIP xTech

Niccolò Silicani
Senior Data Scientist Financial Services
@BIP xTech

Romeo Carrara
Data Scientist Financial Services
@BIP xTech
Context
In our previous article, “Improving Credit Management through AI”, we explored how Artificial Intelligence (AI) was changing the way banks and borrowers work together in the world of credit. We saw how AI made it easier for banks to figure out the risks and helped more people get access to loans on good terms.
Building on this progress, one of the central aspects of credit risk management is the computation of the probability of financial distress: the likelihood that a borrower will encounter financial troubles within one year and consequently be unable to repay its debt. This is a significant aspect because it enables lenders to make informed decisions based on their risk tolerance, aligning with the requirements set by international banking regulations, such as the Basel Accords, which aim to quantify the financial system’s exposure at risk. Predicting when companies might face monetary challenges thus becomes fundamental in ensuring responsible and prudent financial decision-making. This article shows the latest developments in the topic and highlights what BIP xTech to improve to improve and bring innovations.
Traditional methods in Credit Risk management
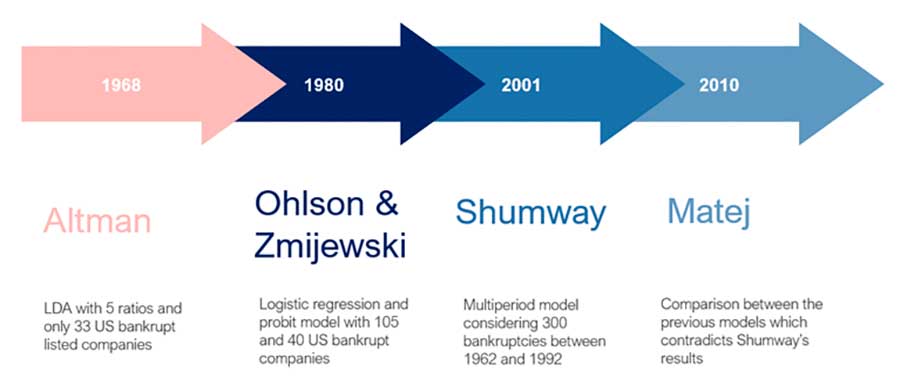
Being the topic of financial distress prediction so crucial, many formulas and models were developed in the past to make predictions about a company’s health. One of the most popular and cited approaches is the Altman z-score. The original formulation goes back to 1968 but it was further revised in 1995 to take into account non-listed companies. It consists of an application of a Linear Discriminant Analysis (LDA) employing four financial ratios: Working Capital to Total Assets (X1), Retained Earnings to Total Assets (X2), EBIT to Total Assets (X3), Equity to Debts (X4). The z-score is computed as follows:
![]()
The higher the value of Z (i.e., the linear combination that better discriminates the two classes of companies: healthy and financially distressed), the lower the likelihood of the company going bankrupt. Other relevant works developed on the American market are linked to Ohlson, Zmijewski, and Shumway employing logistic regression and Cox regression as prediction algorithms.
Machine Learning improvements
The approaches discussed so far based on statistical techniques (regression and LDA) require minimum computational efforts to be built and are easy to understand and interpret. On the other hand, these methods often require strict assumptions about data distribution and aren’t able to deal with non-linear relationships. These limitations consequently decrease the prediction power.
Newer sophisticated techniques from the world of Machine Learning overcome these limitations. They maintain interpretable thanks to several Explainability techniques like Shapley Values while and the computational feasibility of these techniques has been greatly enhanced, thanks to the evolution of cloud computing.
These more powerful models usually outperform the previous statistical methods and can leverage also unstructured alternative data like webpages, videos, images, and other materials which could provide useful insights, further improving the predictive power.
BIP xTech can help
BIP xTech proudly stands as Italy’s premier professional community of data scientists, boasting a formidable society of over 250 data scientists globally. Within this vibrant community, specialized teams immersed in the intricacies of the financial and banking sectors collaborate closely with Italian and international clients, leveraging their extensive experience with data to construct robust credit risk models.
Our teams are here to assist clients from start to finish, guiding them from initial planning and strategy to actual implementation. Our professionals bring a range of skills to the table, including expertise in managing cloud infrastructure, data engineers to handle data pipelines, and data scientists and AI engineers skilled in developing end-to-end Machine Learning models. Moreover, we have domain experts well-versed in banking and regulation and in the end our BI specialists create user-friendly dashboards and data visualizations, ensuring an effective approach to client support.
Our Finance-focused Data Science team applies the power of these advanced Machine Learning tools to enhance credit score algorithms utilized by banks and financial institutions. This translates into improved loan assignment policies, ultimately leading to more efficient resource utilization and cost savings.
Case study: Financial Distress Prediction of Italian companies
THE CHALLENGE
As mentioned before, the majority of the data-driven credit risk literature focuses on the American listed market, due to a larger availability of data. Understanding the need for custom solutions, BIP xTech created a Machine Learning model specifically built for Italy’s business landscape, which is largely made up of Small and Medium Enterprises (SMEs).
The objective was challenging for several reasons:
- In the context of credit risk, datasets are consistently imbalanced, with a significantly smaller proportion of companies facing financial troubles compared to healthy firms. This poses a significant challenge for Machine Learning algorithms.
- The model must be as performant as possible in terms of Accuracy Ratio: a performance metric suggested by the Basel Committee to evaluate credit scoring models. In particular, we aim to outperform the historical model discussed above: the Altman z-score.
- The final model must go beyond binary classification and provide a reliable estimate of distress probability, allowing lenders to take their decisions based on risk tolerance.
- Explainability is required: credit risk models must be approved by regulators. For these reasons, they must be as simple and transparent as possible.
OUR SOLUTION
Starting from the challenges listed above, we aimed to produce a performant and explainable model able to accurately predict the probabilities of financial distress even in contexts of high imbalance. Since no technique has been found to outperform all others on all domains, we looked at various candidate Machine Learning models that might be a good fit for the problem.
First, there’s Logistic Regression, which is straightforward and easy to understand, making it a good choice for Finance. Then, for simpler methods, we considered Decision Trees, which are highly interpretable, and Naïve Bayes, known for its ability to handle imbalanced datasets. Among more complex models, we examined Random Forest and Gradient Boosted Trees (XGBoost and LightGBM as implementation). The latter is also effective at dealing with class imbalance.
Before training the models, the dataset was properly prepared. Starting from an Italian financial database containing financial statement data of the Italian companies, we derived new potential useful features: the traditional financial ratios (like Leverage or ROI) and the changes in time of the variables. The dataset was then pre-processed to deal with missing values, outliers, and redundant features.
After cleaning the dataset, we optimized the models: for each of them the best hyperparameter configuration was found through Bayesian Search while the best feature subset was obtained through Forward Feature Selection. Once that every model was optimized, we compared the performances.
Gradient Boosted Trees (LightGBM and XGBoost) achieved the higher results, thanks to their ability to manage imbalanced datasets. Even if LightGBM performance was slightly superior to XGBoost one, the difference was not statistically significant. We preferred to select XGBoost as final product, due to the lower number of features employed, leading to a simpler model. In any case, we can notice that both models achieve way higher performance when compared to traditional methods like Logistic Regression.
|
Method |
Accuracy Ratio |
N. Features |
Prediction time () |
|
LightGBM |
0.8369 ± 0.0157 |
15 |
1.0733 |
|
XGBoost |
0.8351 ± 0.0190 |
12 |
0.4829 |
|
Logistic Regression |
0.7242 ± 0.039 |
11 |
0.0894 |
RESULTS
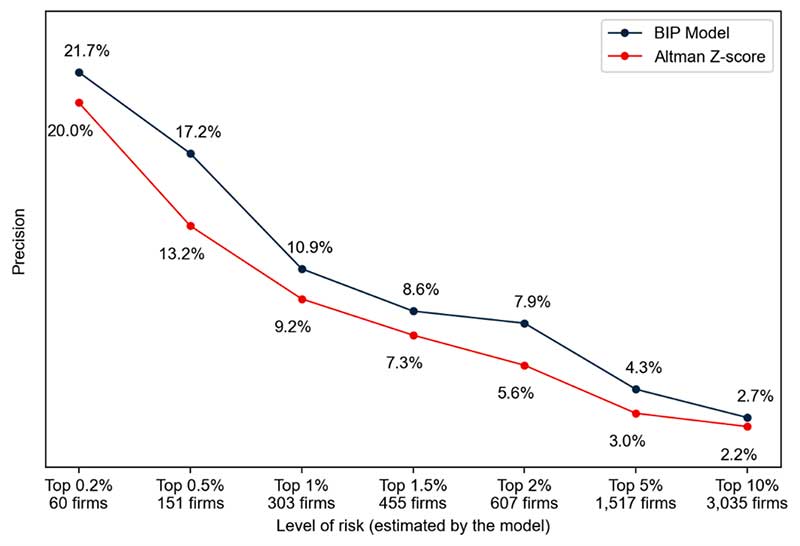
To assess the effectiveness of the suggested model, we employed it to estimate the likelihood of financial distress of over 30,000 Italian companies over the future 12 months. This prediction was made using financial data from prior years. Subsequently, we conducted a comparison of these results with the Altman Z-Score, a well-established historical model for forecasting financial distress.

We look at three main common metrics to evaluate how well the two models can differentiate between financially distressed and healthy companies. Our Machine Learning model outperforms Altman with respect to all of them. In addition, the plot below provides a more dynamic and detailed view of our model’s performance. It showcases the proportion of companies identified as higher risk and the actual fraction of them facing financial distress. This visual representation allows stakeholders and analysts to assess the model’s effectiveness quickly, by highlighting its ability to pinpoint high-risk cases and the extent to which these predictions align with real-world outcomes.
EXPLAINABILITY
A critical aspect of Machine Learning models when applied to credit and other financial sector areas, is their Explainability and compliance with normative and regulations. The recent years have seen a tremendous advancement of Machine Learning in these aspects: powerful Machine Learning models are no longer incomprehensible black boxes.
We applied Shapley Value to identify relevant features and their impact on predicted probabilities. As expected, high values of Equity to Total Assets ratio, financial income, working capital, and group membership reduce the likelihood of financial distress. A non-linear relationship was found in Debts to EBITDA ratio: both too high and too low values increase the probability of financial distress. This is unsurprising: when the ratio is lower, it means the company has fewer debts in relation to its profit, indicating sound business practices. Conversely, if the ratio is too low, potentially falling below zero due to a negative EBITDA, the situation undergoes a significant shift, leading to an elevated probability of financial distress.
Shapley Values offer more than just a global perspective on the most influential factors; they can provide insights into individual predictions as well, highlighting specific actions a company can take to enhance its financial standing. For instance, consider the case of the company being analyzed here. A lower Debts/EBITDA ratio, in comparison to the median value, reduces the risk of financial distress, whereas not being part of a group increases this probability.
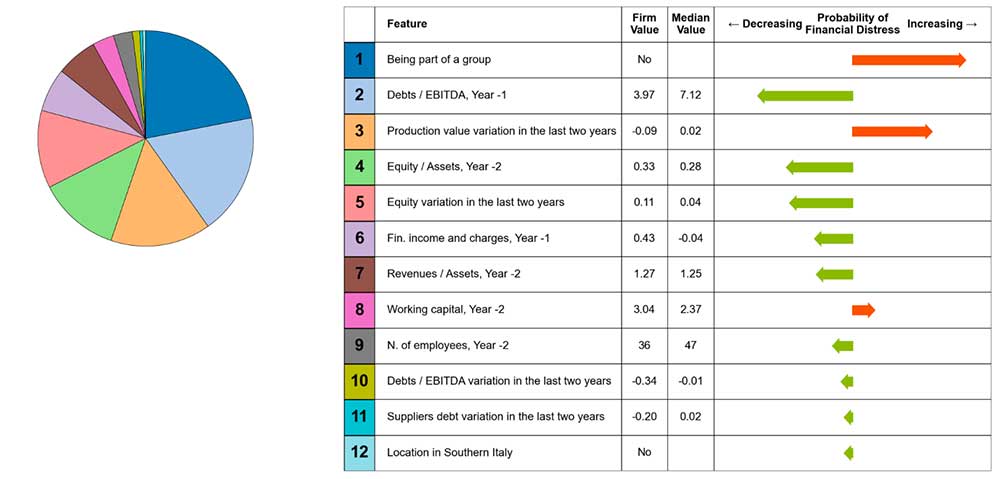
Shapley Values, as demonstrated in our analysis, provide valuable insights into understanding the inner workings of Machine Learning models. However, it is just one of several tools available for interpreting these models. In the ever-evolving field of Machine Learning interpretability, a variety of techniques and methodologies exist. For instance, techniques like feature importance, Partial Dependence Plots (PDP), LIME (Local Interpretable Model-agnostic Explanations), and more have gained prominence. This variety of Explainability tools contributes to the broader goal of building trust in Machine Learning models and their applications, leading to better-informed decision-making in various domains.
Conclusions
In this article we deeply examined the power of Machine Learning in Finance to achieve better performances in terms of potential revenues and risk exposure.
After a quick recap about credit risk management and current approaches to credit risk, we’ve looked closely at how BIP xTech uses advanced Machine Learning to predict corporate financial distress. The new approach outperformed traditional methods like the Altman z-score, leading to a more suitable model for Italy’s unique business landscape, mainly composed of Small and Medium Enterprises.
BIP xTech’s solution includes carefully choosing Machine Learning models, preparing data thoroughly, and fine-tuning the process. The result is a strong and clear model that predicts financial troubles accurately. In a real-world test with Italian companies, BIP xTech’s model proved its worth, helping lenders make better decisions, reducing mistakes and encouraging responsible lending while lowering financial risks.
BIP xTech stands as a valuable partner in the financial sector, offering extensive expertise in Artificial Intelligence, Data Science and Hyperautomation. Our capabilities extend beyond traditional structured data, encompassing unstructured data sources as well like images and webpages. With a proven track record, BIP xTech provides financial institutions with tailored solutions that leverage the most innovative techniques, enabling more informed decision-making and more benefits to its customers. Our commitment to innovation and adaptability makes us a trusted ally for navigating the rapidly evolving landscape of finance.
AUTHORS
Andrea Casati
Director Data&AI Financial Services
@BIP xTech
Gabriella Jacoel
Lead Data Scientist Financial Services
@BIP xTech
Niccolò Silicani
Senior Data Scientist Financial Services
@BIP xTech
Romeo Carrara
Data Scientist Financial Services
@BIP xTech